

Scrape Keywords From A Website
Web Scraping Basics
How to scrape data from a website in Python
![]()
We always say "Garbage in Garbage out" in data science. If you do not have good quality and quantity of data, most likely you would not get many insights out of it. Web Scraping is one of the important methods to retrieve third-party data automatically. In this article, I will be covering the basics of web scraping and use two examples to illustrate the 2 different ways to do it in Python.
What is Web Scraping
Web Scraping is an automatic way to retrieve unstructured data from a website and store them in a structured format. For example, if you want to analyze what kind of face mask can sell better in Singapore, you may want to scrape all the face mask information on an E-Commerce website like Lazada.
Can you scrape from all the websites?
Scraping makes the website traffic spike and may cause the breakdown of the website server. Thus, not all websites allow people to scrape. How do you know which websites are allowed or not? You can look at the 'robots.txt' file of the website. You just simply put robots.txt after the URL that you want to scrape and you will see information on whether the website host allows you to scrape the website.
Take Google.com for an example
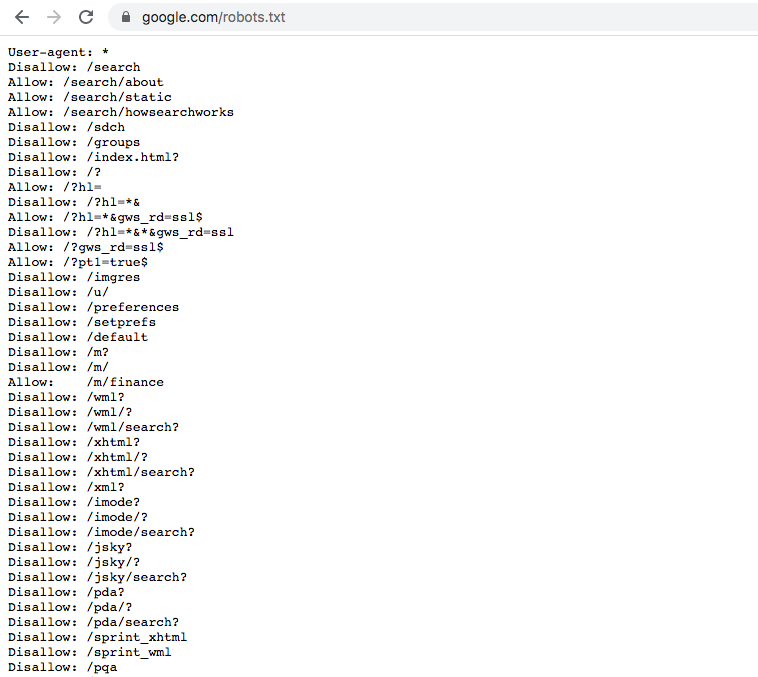
You can see that Google does not allow web scraping for many of its sub-websites. However, it allows certain paths like '/m/finance' and thus if you want to collect information on finance then this is a completely legal place to scrape.
Another note is that you can see from the first row on User-agent. Here Google specifies the rules for all of the user-agents but the website may give certain user-agent special permission so you may want to refer to information there.
How does web scraping work?
Web scraping just works like a bot person browsing different pages website and copy pastedown all the contents. When you run the code, it will send a request to the server and the data is contained in the response you get. What you then do is parse the response data and extract out the parts you want.
How do we do web scraping?
Alright, finally we are here. There are 2 different approaches for web scraping depending on how does website structure their contents.
Approach 1: If website stores all their information on the HTML front end, you can directly use code to download the HTML contents and extract out useful information.
There are roughly 5 steps as below:
- Inspect the website HTML that you want to crawl
- Access URL of the website using code and download all the HTML contents on the page
- Format the downloaded content into a readable format
- Extract out useful information and save it into a structured format
- For information displayed on multiple pages of the website, you may need to repeat steps 2–4 to have the complete information.
Pros and Cons for this approach: It is simple and direct. However, if the website's front-end structure changes then you need to adjust your code accordingly.
Approach 2: If website stores data in API and the website queries the API each time when user visit the website, you can simulate the request and directly query data from the API
Steps:
- Inspect the XHR network section of the URL that you want to crawl
- Find out the request-response that gives you the data that you want
- Depending on the type of request(post or get) and also the request header & payload, simulate the request in your code and retrieve the data from API. Usually, the data got from API is in a pretty neat format.
- Extract out useful information that you need
- For API with a limit on query size, you will need to use 'for loop' to repeatedly retrieve all the data
Pros and Cons for this approach: It is definitely a preferred approach if you can find the API request. The data you receive will be more structured and stable. This is because compared to the website front end, it is less likely for the company to change its backend API. However, it is a bit more complicated than the first approach especially if authentication or token is required.
Different tools and library for web scraping
There are many different scraping tools available that do not require any coding. However, most people still use the Python library to do web scraping because it is easy to use and also you can find an answer in its big community.
The most commonly used library for web scraping in Python is Beautiful Soup, Requests, and Selenium.
Beautiful Soup: It helps you parse the HTML or XML documents into a readable format. It allows you to search different elements within the documents and help you retrieve required information faster.
Requests: It is a Python module in which you can send HTTP requests to retrieve contents. It helps you to access website HTML contents or API by sending Get or Post requests.
Selenium: It is widely used for website testing and it allows you to automate different events(clicking, scrolling, etc) on the website to get the results you want.
You can either use Requests + Beautiful Soup or Selenium to do web scraping. Selenium is preferred if you need to interact with the website(JavaScript events) and if not I will prefer Requests + Beautiful Soup because it's faster and easier.
Web Scraping Example:
Problem statement: I want to find out about the local market for face mask. I am interested on online face mask price, discount, ratings, sold quantity etc.
Approach 1 Example(Download HTML for all pages) — Lazada:
Step 1: Inspect the website(if using Chrome you can right-click and select inspect)
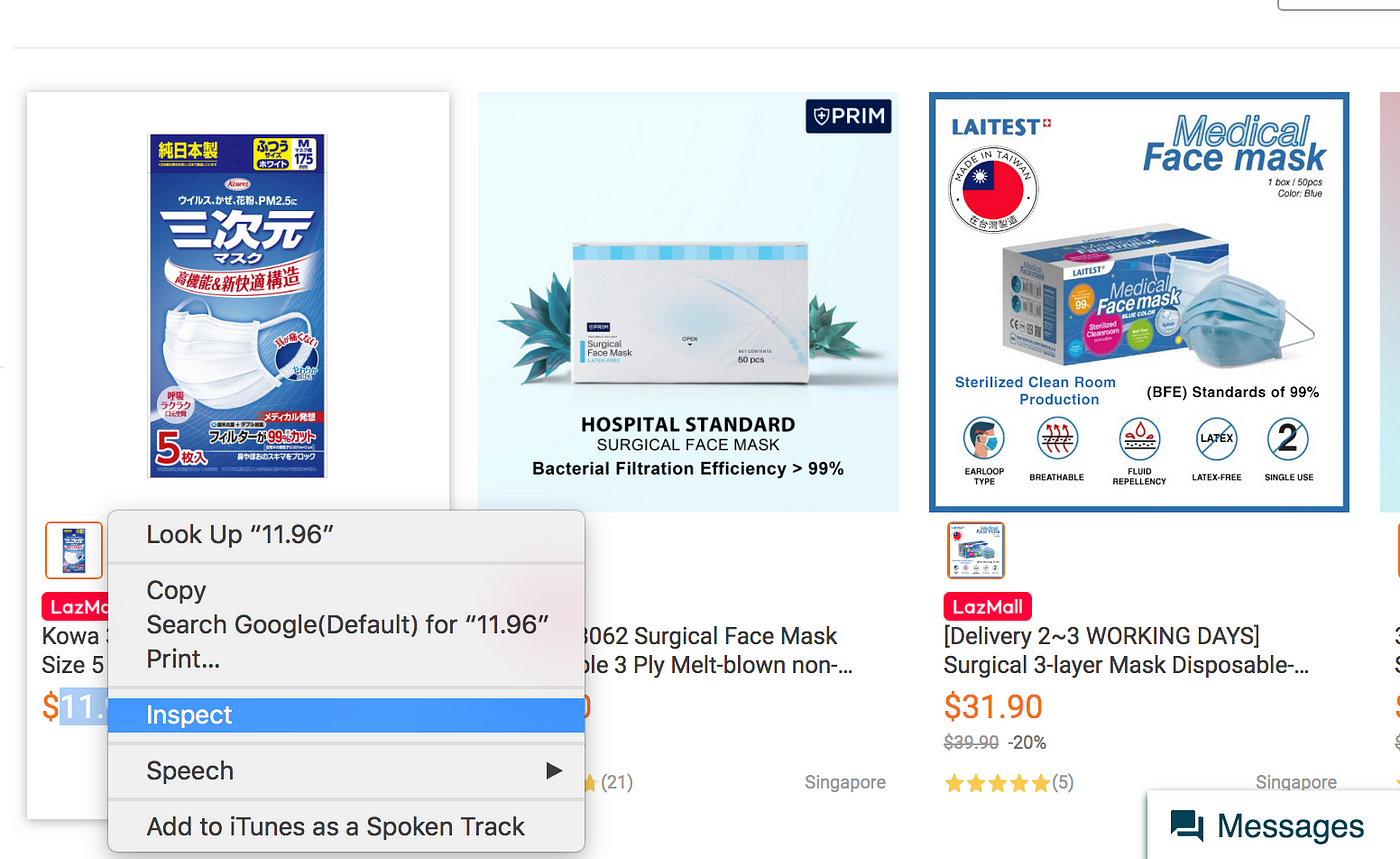
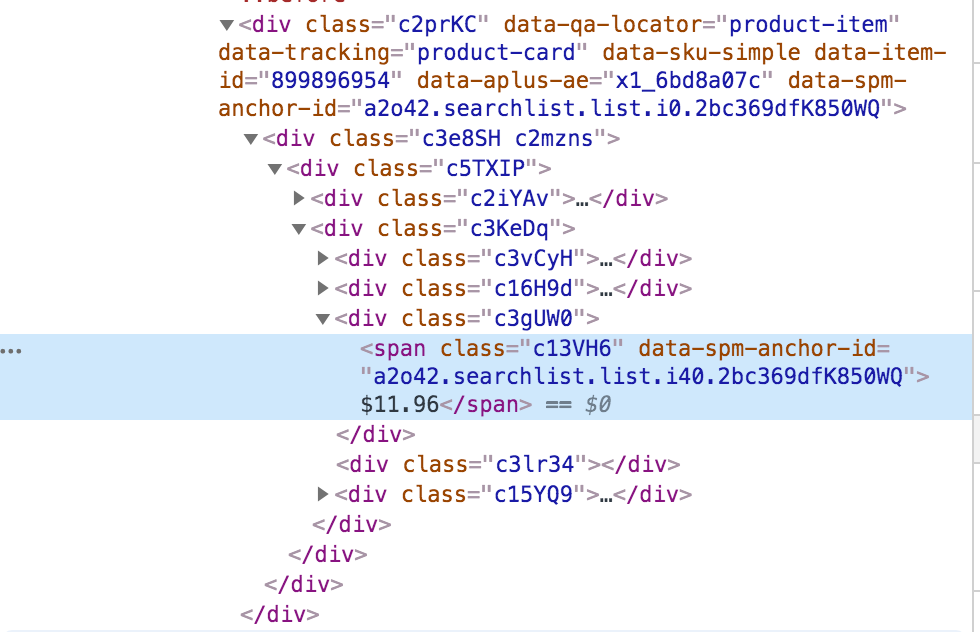
I can see that data I need are all wrap in the HTML element with the unique class name.
Step 2: Access URL of the website using code and download all the HTML contents on the page
# import library
from bs4 import BeautifulSoup
import requests # Request to website and download HTML contents
url='https://www.lazada.sg/catalog/?_keyori=ss&from=input&q=mask'
req=requests.get(url)
content=req.text
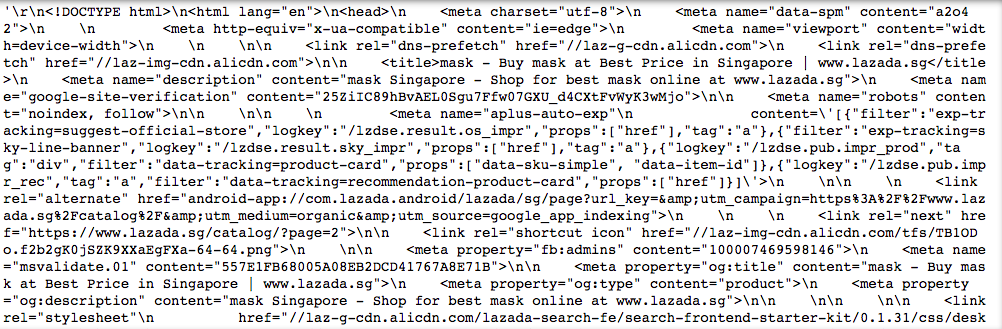
I used the requests library to get data from a website. You can see that so far what we have is unstructured text.
Step 3: Format the downloaded content into a readable format
soup=BeautifulSoup(content) This step is very straightforward and what we do is just parse unstructured text into Beautiful Soup and what you get is as below.
The output is a much more readable format and you can search different HTML elements or classes in it.
Step 4: Extract out useful information and save it into a structured format
This step requires some time to understand website structure and find out where the data is stored exactly. For the Lazada case, it is stored in a Script section in JSON format.
raw=soup.findAll('script')[3].text
page=pd.read_json(raw.split("window.pageData=")[1],orient='records')
#Store data
for item in page.loc['listItems','mods']:
brand_name.append(item['brandName'])
price.append(item['price'])
location.append(item['location'])
description.append(ifnull(item['description'],0))
rating_score.append(ifnull(item['ratingScore'],0)) I created 5 different lists to store the different fields of data that I need. I used the for loop here to loop through the list of items in the JSON documents inside. After that, I combine the 5 columns into the output file.
#save data into an output
output=pd.DataFrame({'brandName':brand_name,'price':price,'location':location,'description':description,'rating score':rating_score}) 
Step 5: For information displayed on multiple pages of the website, you may need to repeat steps 2–4 to have the complete information.
If you want to scrape all the data. Firstly you should find out about the total count of sellers. Then you should loop through pages by passing in incremental page numbers using payload to URL. Below is the full code that I used to scrape and I loop through the first 50 pages to get content on those pages.
for i in range(1,50):
time.sleep(max(random.gauss(5,1),2))
print('page'+str(i))
payload['page']=i
req=requests.get(url,params=payload)
content=req.text
soup=BeautifulSoup(content)
raw=soup.findAll('script')[3].text
page=pd.read_json(raw.split("window.pageData=")[1],orient='records')
for item in page.loc['listItems','mods']:
brand_name.append(item['brandName'])
price.append(item['price'])
location.append(item['location'])
description.append(ifnull(item['description'],0))
rating_score.append(ifnull(item['ratingScore'],0)) Approach 2 example(Query data directly from API) — Ezbuy:
Step 1: Inspect the XHR network section of the URL that you want to crawl and find out the request-response that gives you the data that you want
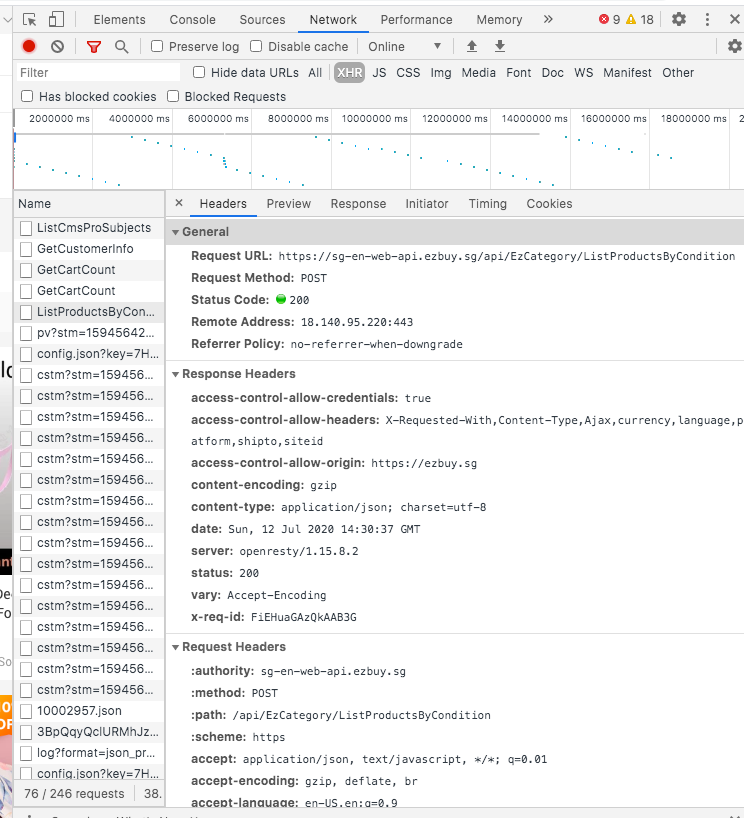
I can see from the Network that all product information is listed in this API called 'List Product by Condition'. The response gives me all the data I need and it is a POST request.
Step 2: Depending on the type of request(post or get) and also the request header & payload, simulate the request in your code and retrieve the data from API. Usually, the data got from API is in a pretty neat format.
#Define API url
url_search='https://sg-en-web-api.ezbuy.sg/api/EzCategory/ListProductsByCondition' #Define header for the post request
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'} #Define payload for the request form
data={
"searchCondition":
{"categoryId":0,"freeShippingType":0,"filter: [],"keyWords":"mask"},
"limit":100,
"offset":0,
"language":"en",
"dataType":"new"
}
req=s.post(url_search,headers=headers,json=data)
Here I create the HTTP POST request using the requests library. For post requests, you need to define the request header(setting of the request) and payload(data you are sending with this post request). Sometimes token or authentication is required here and you will need to request for token first before sending your POST request. Here there is no need to retrieve the token and usually just follow what's in the request payload in Network and define 'user-agent' for the header.
Another thing to note here is that inside the payload, I specified limit as 100 and offset as 0 because I found out it only allows me to query 100 data rows at one time. Thus, what we can do later is to use for loop to change offset and query more data points.
Step 3: Extract out useful information that you need
#read the data back as json file
j=req.json() # Store data into the fields
for item in j['products']:
price.append(item['price'])
location.append(item['originCode'])
name.append(item['name'])
ratingScore.append(item['leftView']['rateScore'])
quantity.append(item['rightView']['text'].split(' Sold')[0] #Combine all the columns together
output=pd.DataFrame({'Name':name,'price':price,'location':location,'Rating Score':ratingScore,'Quantity Sold':quantity})
Data from API is usually quite neat and structured and thus what I did was just to read it in JSON format. After that, I extract the useful data into different columns and combine them together as output. You can see the data output below.
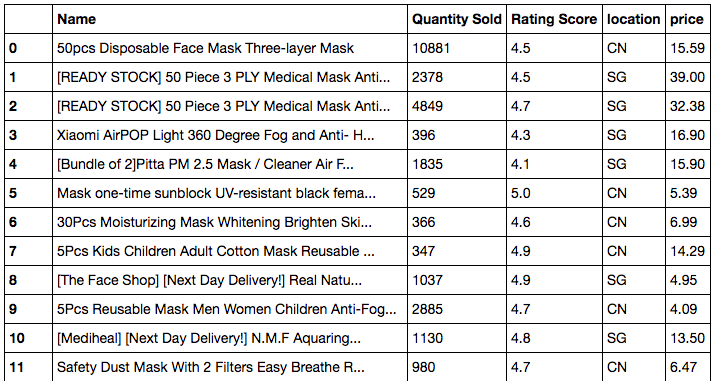
Step 4: For API with a limit on query size, you will need to use 'for loop' to repeatedly retrieve all the data
#Define API url
url_search='https://sg-en-web-api.ezbuy.sg/api/EzCategory/ListProductsByCondition' #Define header for the post request
headers={'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'} for i in range(0,14000,100):
time.sleep(max(random.gauss(3,1),2))
print(i)
data={
"searchCondition":
{"categoryId":0,"freeShippingType":0,"filters":
[],"keyWords":"mask"},
"limit":100,
"offset":i,
"language":"en",
"dataType":"new"
}
req=s.post(url_search,headers=headers,json=data)
j=req.json()
for item in j['products']:
price.append(item['price'])
location.append(item['originCode'])
name.append(item['name'])
ratingScore.append(item['leftView']['rateScore'])
quantity.append(item['rightView']['text'].split(' Sold')[0]) #Combine all the columns together
output=pd.DataFrame({'Name':name,'price':price,'location':location,'Rating Score':ratingScore,'Quantity Sold':quantity})
Here is the complete code to scrape all rows of face mask data in Ezbuy. I found that the total number of rows is 14k and thus I write a for loop to loop through incremental offset number to query all the results. Another important thing to note here is that I put a random timeout at the start of each loop. This is because I do not want very frequent HTTP requests to harm the traffic of the website and get spotted out by the website.
Finally, Recommendation
If you want to scrape a website, I would suggest checking the existence of API first in the network section using inspect. If you can find the response to a request that gives you all the data you need, you can build a stable and neat solution. If you cannot find the data in-network, you should try using requests or Selenium to download HTML content and use Beautiful Soup to format the data. Lastly, please use a timeout to avoid a too frequent visits to the website or API. This may prevent you from being blocked by the website and it helps to alleviate the traffic for the good of the website.
Scrape Keywords From A Website
Source: https://towardsdatascience.com/web-scraping-basics-82f8b5acd45c
Posted by: shawpuble1956.blogspot.com
0 Response to "Scrape Keywords From A Website"
Post a Comment